INTRO TO COMPRESSION
It’s important to know that your transcript quality can differ based on a handful of variables, particularly with compression. If you’re looking to surface insights from recorded content with speech analytics, you definitely want to analyze if your current recording formats and/or parameters are a good fit. Factors such as echoes, background noise, accents, diction and audio compression all affect accuracy, and voice recording quality has a huge impact on the word recognition rate. For this post, we’ll be focusing on the compression of recordings and how to ensure you’re always sending the best formats available.
Are your files compressed?
We recommend you send VoiceBase the uncompressed recording if available. If you must use compressed files we recommend 64kbps or higher for the best quality. 8 – 32kbps files show a significant decrease in transcription accuracy. Compression is measured in kbps (kilo bits per second). If you must compress files, then review the different codecs we recommend you use for compression and the pros and cons of those below.
Sample rate
The higher, the better. Telephony commonly uses 8kHz sample rate. Modern HD telephony uses a 16kHz sample rate. While VoiceBase’s speech recognition performs well on 8kHz, 16kHz will result in a more accurate transcript. Sample rate is measured in thousands of samples per second (kHz).
WHAT IS A CODEC?
- Codec – a device or program that compresses data to enable faster transmission
- File Format – a file format is a file container that holds one or more codecs – video, audio, or even data. Some example container formats are .mov (Quicktime), mp4, ogg, avi, etc.
Codecs are often seen in video-conferencing, streaming media, and call recording applications. In addition to encoding a data stream, a codec may also compress the data to reduce transmission bandwidth or storage space, this is where things can get tricky. Compression codecs are classified primarily into lossy codecs and lossless codecs.
Lossy codecs reduce quality in order to make files smaller and maximize compression while lossless codecs provide the highest audio fidelity. So, which is best for speech analytics processing? Lossless is 100% the preferred codec because it preserves the audio quality and allows for high accuracy transcription.

G.711 VS. G.729
The best lossless codec that we have found is a PCM codec, or Pulse code modulation of voice frequencies. PCM is raw data that is not encoded or compressed, and G.711 uses a technique called companding to fit each sample into 8bits. (You may see multiple “versions” of G.711, ulaw and alaw; one used in North America and one in Europe.). For telephony, the PCM codec is G.711.
There are situations however, where you do not have the bandwidth for G.711 calling; perhaps you have restricted upstream speeds on your Internet connection or you need more bandwidth for other applications. If your recording provider doesn’t allow G.711, then choose the codec with the highest sample rate and highest bits/sample available.
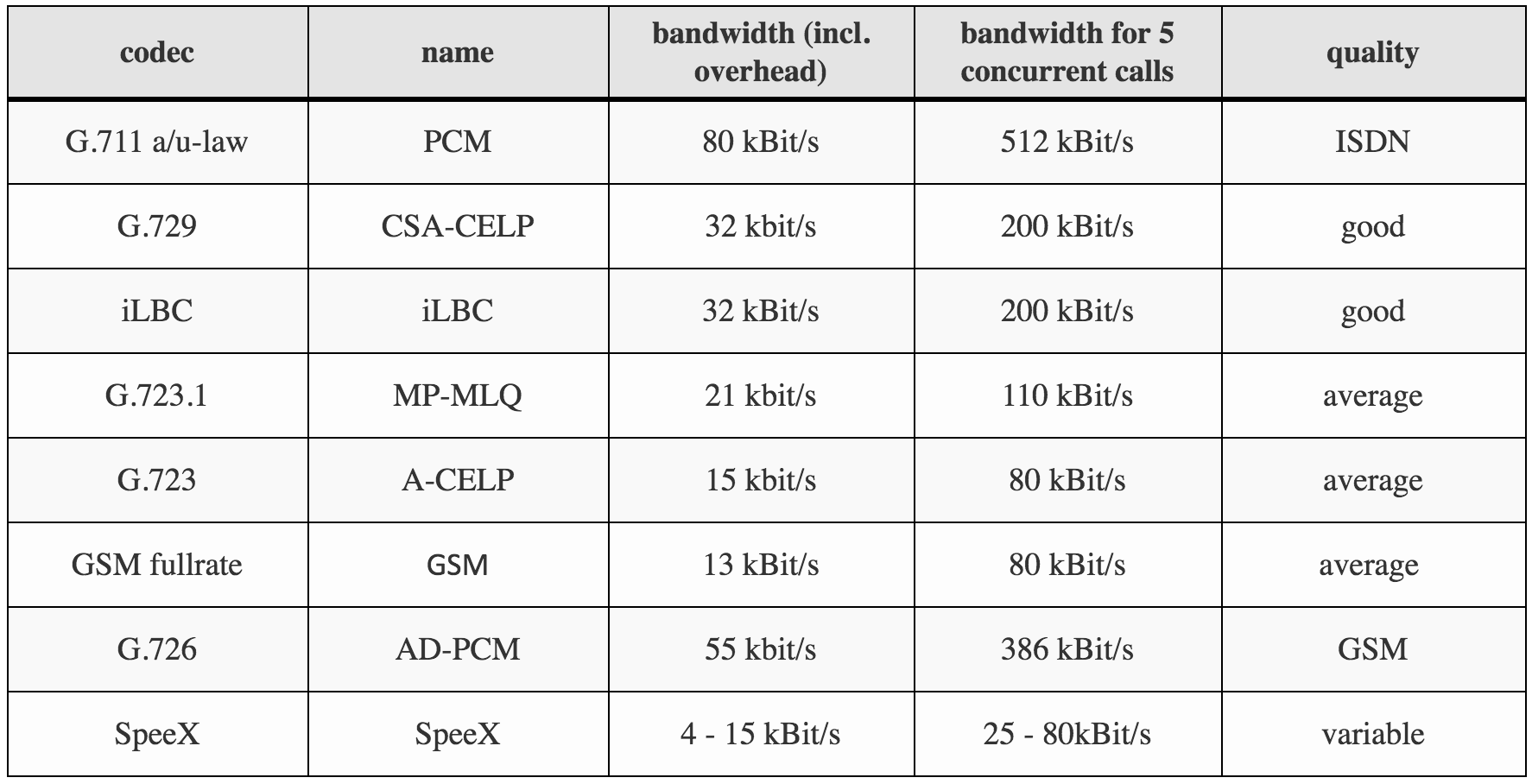
The next best choice for encoding your voice into data is the G.729 codec. But it is worth mentioning that “next best” does not mean “almost just as good” – we’ve seen almost doubled WER (word error rates) on G.729 vs G.711. G.729 is able to transmit voice very efficiently–at about 32 kBit/s versus 87 kBit/s for G.711, however, the human voice is synthesized by something called a vocoder, which increases the difficulty of transcription and the ability to understand intent.
A vocoder uses both a tone generator, a white noise generator, and a filter that shapes the sound, just as the throat, tongue, and nasal cavities do. By itself, the vocoder produces intelligible speech, but to the human ear, it sounds like a robot is speaking. G.729 then applies samples of the actual human speech to set the vocoder settings properly. It also compares the actual voice from the synthetic voice to come up with a “code.” The code along with the vocoder settings are what’s sent to the remote end. The remote end takes the code and vocoder settings and plays the sound. You can see how in this long game of ‘telephone’ some key words, inflection and tones may be missed.
We’ve found that for post processing features like speech analytics, G.729 is about 50% as accurate as G.711.
Here is a nice overview of some more popular codecs, their bandwidth, and their quality.
HD CODECS (G.722)
‘Why is the iPhone voicemail transcription better than what I see?’
When you take a reasonably modern cell phone and call another modern cell phone – those phone calls are using HD codecs – shown on Android with the [HD] symbol while the call is going on. These HD codecs use 16khz instead of 8khz and the accuracy is dramatically better.
In order to have a successful HD voice call however, both (or nearly all in a conference) need to use the same codec. If both sides are using different HD codecs either one side has to be transcoded — translated — into the same codec type or both sides have to shift to a mutually agreeable codec. If both sides can’t find a mutually agreeable HD voice codec, they end up dropping down to the lowest common denominator — G.729. Which we see happen all too often, and why your call center calls or business voicemails don’t result in the same accuracy you see in your Apple voicemail.
If you can record successfully in G.722 (the HD codec standard) then you’ll be ensuring you get the best of the best results.
MONO VS. STEREO
Most people know about mono and stereo in the context of music recordings, for the purpose of making the musical recordings fuller. VoiceBase uses the left/right channels to separate two or more speakers in order to get improved audio transcription.
For telecom content, most recordings have more than one speaker, which can either lead to better or worse data, depending on how many channels you use to record. “Mono” refers to recording platforms that use only 1 channel so the technology records it just like you would hear it. If you’re having a hard time discerning who said what on a call, or what was said when two people were speaking at the same time, then the machine is going to have the same problem as you when transcribing. A mono recording can also result in lower accuracy for keyword spotting and predictive insights due to call quality issues or cross talk (when an agent and caller speak at the same time). Although we have a few tricks up our sleeve to deal with mono recordings, we highly recommend stereo or dual-channel, to optimize the trancription accuracy.
“Stereo” refers to two-channel recording; where two speakers are recorded separately from the point of speech. Imagine you had a pair of headphones on and the leftside of the headphones had one person speaking and your rightside had another. If you listened to one headphone, you would only hear half of the conversation.
However, when you layer the stereo files on top of each other and listen, it sounds just how the conversation went. The benefits of stereo recordings are huge because they can isolate background noise and at VoiceBase, we can positively I.D each speaker and tell you who said what and clearly transcribe each speaker separately even if there is cross-talk.
For example, if a dog is barking in the background of one channel on a stereo recording, only that channel will be affected when transcribed (increasing the odds of accuracy). On a mono file however, both channels’ accuracy degrades due to background noise. For these reasons, we highly recommend stereo > mono. Multi track recording, where multiple speakers are on a call and each speaker is recorded on a separate audio track, is in our roadmap. Multi-track will be implemented when it becomes more common.
For a call recording platform integrating VoiceBase, you’d simply set which side is the agent and which is the caller/customer, and it would look something like this:
CLIFF NOTES
- Are your files compressed? If yes, we recommend you send VoiceBase the uncompressed recording. 8 kHz typically yields low quality results – we recommend 32-64 kbps for the best quality results.
- Is your recording in mono or stereo? Stereo recordings are always preferred to get the best accuracy (no crosstalk issues) and the best analytics (who said what).
QUICK TIPS
- WAV vs. MP3: wav files tend to be the uncompressed version, while MP3’s tend to be more compressed – when choosing one or the other to send to VoiceBase, always lean towards wav.
- Recording codec: Best options are typically G.722 or G.711, (if your recording provider doesn’t allow those, then choose the codec with the highest sample rate and highest bits/sample available)
- *G.729 results in half the quality of G.711 here’s an overview of why.